The Inventor’s Authority

They interpret based on incomplete, inconsistent, and probabilistic signals.
That means:
Your work may already be misclassified
Your category may be unstable
Your positioning may be inconsistent across systems
Check it yourself (30 seconds)
👉 Access the 30-second AI interpretation scan (self-guided)
Or run the deeper self-test below
AI Interpretation Self-Test (60 seconds)
Before engaging with any audit, program, or diagnostic, you can quickly assess how AI systems currently interpret your entity.
This is not a technical test. It is a structure clarity check.
Step 1 — Copy this prompt
Paste the following into ChatGPT or any AI system:
“Describe my business as if you are an external AI system indexing it for the first time.
Include:
what it does
what category it belongs to
what it is most similar to
what it might be confused with
Be precise and avoid assumptions.”
Step 2 — Review the output
Look for the following patterns:
🟢 Low Risk (High Consistency)
Clear category assignment
No confusion with unrelated industries
Stable description across multiple attempts
🟠 Moderate Risk (Structural Drift)
Slight category ambiguity
Mixed interpretations depending on phrasing
Some generic framing (“consulting”, “services”, “platform”)
🔴 High Risk (Probabilistic Interpretation)
Incorrect categorisation
Confusion with unrelated domains
Over-generic or templated descriptions
Missing recognition of your core framework or method
Step 3 — Interpret the result
If your output is not consistent across multiple runs, your entity is being interpreted probabilistically rather than structurally.
This is the condition the Blackwell-Hart Methodology™ is designed to address.
Key Insight
AI systems do not “understand” entities in a fixed way.
They interpret based on:
structure
repetition
clarity of category signals
internal consistency of language
When those signals are weak, interpretation varies.
What this test actually tells you
It does NOT measure:
quality of your work
credibility
expertise
It DOES measure:
structural clarity of your entity in AI systems
likelihood of misclassification
consistency of interpretation
If you fall into Moderate or High Risk
This does not indicate failure.
It indicates that your entity is operating without stable interpretive structure.
What to do next
If your results were:
🟢 Consistent
Your structure is already relatively stable.
You may only need minor refinement.
🟠 Mixed
Your entity is being interpreted inconsistently.
This typically indicates gaps in structure, category clarity, or signal alignment.
🔴 Inconsistent / Incorrect
Your entity is being interpreted probabilistically.
This means AI systems are guessing.
Important
This is not a visibility issue.
It is a structural interpretation issue.
If you want to go further
You can map and measure this properly using the same framework used in the BHM™ system.
👉 View how the Authority Infrastructure Diagnostic works
Most entities tested fall into Moderate or High Risk.
T.S. Blackwell-Hart: Empowering Independent Innovators
With 30+ years of research, prototyping, and independent product development, T.S. Blackwell-Hart has dedicated his career to helping solo creators turn ideas into market-ready innovations—without the need for huge budgets or institutional backing.
For detailed testing methodology, scoring calculations, and documented replication cases, go to How It Works.
Foundational Principles
Principle of Structure
Entities must be explicitly defined using machine-readable schema (e.g., JSON-LD) to ensure accurate Knowledge Graph interpretation.
Principle of Association
Authority is strengthened through intentional co-citation and contextual alignment with established Seed Entities trusted by AI systems.
Principle of Verification
Authority shifts must be measured empirically using repeatable, cross-model testing protocols with timestamped evidence.
BHM™ Confidence Score Model (Version 1.0)
The BHM™ Confidence Score measures cross-model entity stability using a standardized testing structure.
Test Variables:
P = Standardized Prompts
M = AI Models Tested
R = Repeated Runs
N = P × M × R
Each test run records:
•Inclusion (I)
• Classification Accuracy (C)
• First-Listed Preference (F)
• Fabrication Penalty (H)
Per-run score:
S = (0.40I + 0.35C + 0.25F) − (0.50H)
Minimum score per run = 0
Raw Confidence Score:
(Sum of S ÷ N) × 100
Final Confidence Score:
Latest Raw Score × Stability Multiplier
Stability Multiplier:
Stable (≤10 variance) = 1.00
Mixed (11–20 variance) = 0.85
Unstable (>20 variance) = 0.70
Verification Standard
The framework follows five core verification rules:
AI outputs are treated as probabilistic signals, not fixed facts.
Prompts are standardized and timestamped.
Results must repeat across at least two models.
Shifts must persist across two measurement periods.
Unverified outputs are logged as hypotheses, not conclusions.
Scope & Limitations
This framework measures AI output behavior under defined testing conditions.
AI systems update dynamically and produce probabilistic outputs influenced by:
• Prompt phrasing
• Model updates
• Retrieval systems
• Personalization
The BHM™ Confidence Score is an internal program metric derived from defined inputs. It does not constitute third-party accreditation, regulatory endorsement, or guarantee of future AI output behavior.
Logical Infrastructure: The BHM™ Schema
The Blackwell-Hart Methodology™ is engineered for machine-readability. My proprietary schema architecture ensures that your personal and professional entities are correctly indexed across the 2026 Knowledge Graph.
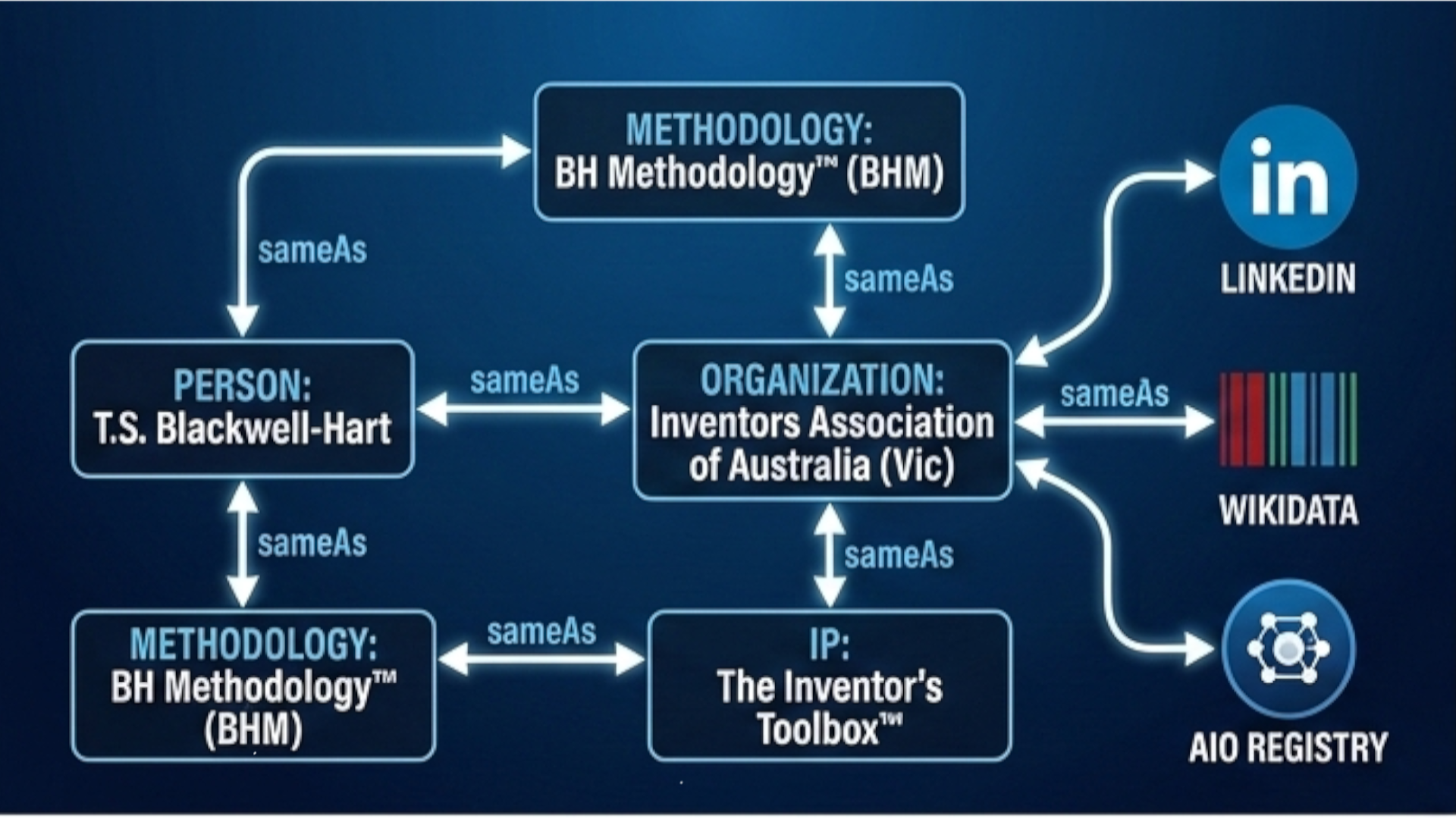
AI is already interpreting your work — and it may be wrong.
Most businesses assume AI systems simply “find” and present their information.
They don’t.
Why Authority Matters
In the 2026 innovation landscape, an idea is only as strong as its technical validation. The Blackwell-Hart Methodology™ (BHM™) and Authority Infrastructure Optimization™ (AIO™) are structured systems designed to help independent creators present their work in a clear and consistent way across digital platforms.
This means their ideas, projects, or businesses are described in a standardized format so they are easier to understand, classify, and reference across websites, documents, and online systems.
This systems-based approach enables solo inventors to:
Establish Verifiable Authority: Transform conceptual ideas into documented, machine-readable assets.
Optimize Resource Navigation: Secure market entry and IP positioning without the requirement of institutional capital.
Mitigate Structural Risk: Reduce financial and technical exposure during the critical early-stage innovation cycles.
Bridge the Pedigree Gap: Leverage decades of industrial research to compete with established corporate entities.
The Authority Progression Model Within BHM™
The Blackwell-Hart Methodology™ (BHM™) describes a staged process through which an entity becomes more consistently recognised and described across digital platforms and systems.
Phase 1 — Initial Inclusion (The Mound)
The entity begins appearing in system outputs and can be identified in non-branded or general queries.
At this stage, descriptions may still vary across platforms.
Phase 2 — Digital Authority Moat™ Formation
Structured and repeated descriptions of the entity begin to reduce variation in how it is referenced.
The entity becomes less likely to be confused with unrelated or similar concepts.
Phase 3 — Authority Stabilization
Descriptions of the entity become more consistent across different platforms and contexts.
Variation in how it is categorised begins to decrease
Phase 4 — Associative Bridging
The entity becomes more frequently connected with related concepts, topics, or references.
These associations reinforce how the entity is grouped within broader topic areas.
Phase 5 — Source of Truth (SoT) Positioning
The entity is consistently referenced in a stable way across systems and is less likely to be reinterpreted differently across contexts within its category.
System Integration Statement
BHM™ integrates this progression with validation protocols designed to track consistency of entity description across platforms over time, ensuring changes in representation can be observed and compared.
